





Ollama란?
– Ollama는 로컬 환경에서 오픈소스 기반의 대규모 언어 모델(LLM: Large Language Model)을 손쉽게 실행할 수 있도록 도와주는 도구입니다.
Mac, Windows, Linux 등 다양한 운영체제를 지원하며, GPU가 있다면 더욱 빠르게 실행할 수 있습니다. 명령어 한 줄만 입력하면 모델이 자동으로 다운로드되고 실행되기 때문에, 복잡한 설정 없이도 AI 모 델을 쉽게 활용할 수 있다는 점이 가장 큰 특징입니다.
* Ollama의 특징
| ✅ 로컬 실행 | 클라우드가 아닌 내 컴퓨터에서 직접 모델 실행 가능 (보안성 ↑, 속도 ↑) |
| 📦 다양한 모델 지원 | LLaMA 2, Mistral, Gemma 등 유명 LLM 모델들을 명령어로 실행 가능 |
| 🧩 개발자 친화적 | Python/JavaScript SDK를 제공해 앱과 연동 가능 |
| 🛠️ 커스터마이징 가능 | Modelfile을 사용해 모델 파인튜닝 및 사용자 정의 가능 |
| 🖥️ CPU/GPU 실행 모두 지원 | GPU가 없어도 동작하며, GPU가 있다면 훨씬 빠름 |
서버의 운영체제와 사양은 다음과 같습니다.
– OS : Ubuntu 22.04
* Ollama 설치
# apt -y update
# apt -y upgrade
# curl -fsSL https://ollama.com/install.sh | sh
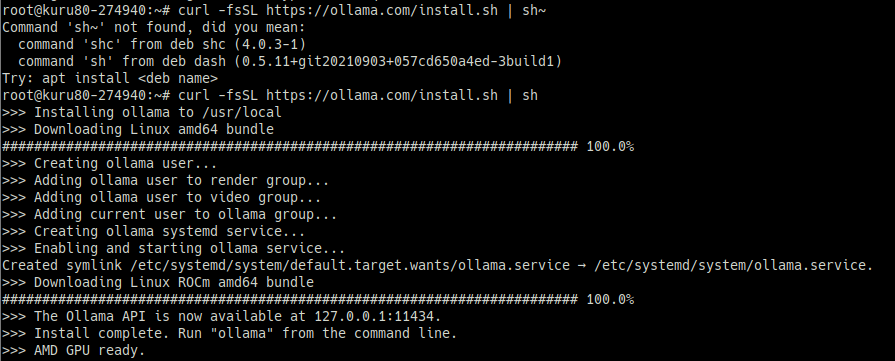
– ollama 설치를 하면 가지고 있는 GPU을 확인을 해줍니다. 원활한 사용을 위해서 GPU 드라이버를 설치가 필요할 수 있습니다.
정상적으로 설치가 되었는지 확인이 필요합니다.
# netstat -ntlp

– ollama의 127.0.0.01로 되어있는 부분은 로컬에서만 접근이 가능한 부분으로 외부에서 접근이 어렵습니다.
– 외부에서 접근을 하기 위해서는 다음과 같은 설정 추가 해주어야 하며, 설정파일을 수정할떄에는 항상 백업본을 만들고 작업을 하는게 좋습니다.
# vi /etc/systemd/system/ollama.service
[Service]
User=root
Environment=”OLLAMA_HOST=0.0.0.0″
[Install]
WantedBy=multi-user.target
# systemctl restart ollama
– [ 서버 IP ]:11434로 접근을 해줍니다. 방화벽에 막혀있는 경우 방화벽을 오픈해주어야지 접근이 가능합니다.
– 접근 후 웹페이지에서 해당 문구가 보이면 정상적으로 설치가 된겁니다.
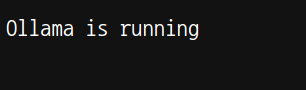
* Ollama을 통해 언어 모델 설치
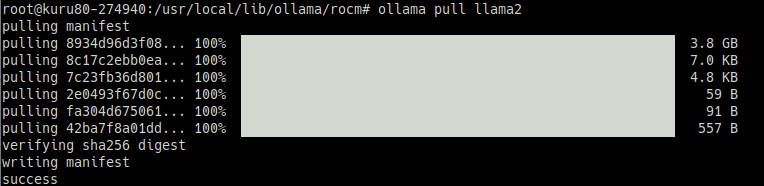
– 모델을 다운해줍니다.
# ollama pull llama2
– 모델 다운 후 시작하여 터미널 내에서 확인해볼 수 있습니다.
# ollama run llama2

# ollama run deepseek-r1:32b
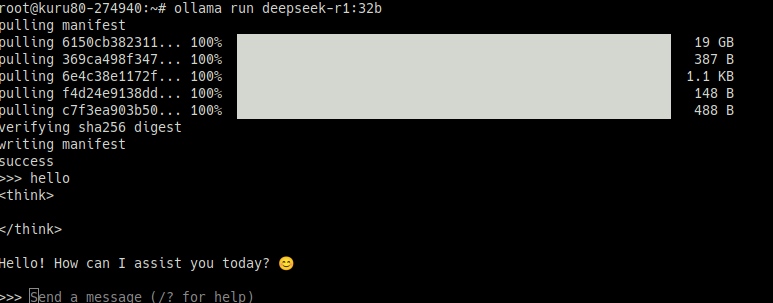
– https://ollama.com ollama 공식 홈페이지에서 모델들을 검색하여 모델들을 다운받아 로컬에서 여러 모델들을 사용해볼 수 있습니다.
* Ollama 정리
-
Ollama는 AI 언어모델을 로컬에서 안전하게 실행할 수 있도록 돕는 경량화 플랫폼입니다.
-
Ubuntu 기반 서버뿐 아니라 Windows, macOS에서도 설치가 가능하며, Docker 없이도 간단하게 실행할 수 있습니다.
-
GPT 기반 언어 모델을 내부 서버나 개인 PC에서 실험하고 싶은 개발자에게 매우 적합합니다.