





0. 테스트 환경 정보
> 테스트 진행 서버 환경 : Rocky 9 서버 1대
> ClickHouse 버전 : 25.10.1
> 설치 방식 : 공식 RPM 패키지
1. Clickhouse?
01. 개요
-
열(Column) 기반 OLAP DBMS
-
대량 데이터 조회와 통계, 로그 분석 최적화
-
실시간 분석과 BI 용도로 사용
02. 특징
-
열 단위 저장: 필요한 컬럼만 읽어서 I/O 효율 높음
-
벡터화 처리 + 멀티스레드: CPU 자원 최대 활용
-
데이터 압축(LZ4, ZSTD 등): 저장 공간 절약
-
분산 처리 가능: 단일 서버부터 클러스터까지 지원
03. 사용 사례
-
웹/서버 로그 분석
-
매출·트래픽 통계, A/B 테스트 결과 집계
-
실시간 대시보드용 데이터 제공
04. MySQL/PostgreSQL과 차이
-
MySQL/PostgreSQL → OLTP, 트랜잭션 중심
-
ClickHouse → 조회·집계 중심, 업데이트/삭제는 제한적
05. OLAP(Online analytical processing)?
- 온라인 분석 처리(OLAP)는 다양한 관점에서 비즈니스 데이터를 분석하는 데 사용할 수 있는 소프트웨어 기술.
- 분석 쿼리를 처리할 목적으로 구축된 데이터 베이스
- 분석쿼리 (복잡한 쿼리)
- 실시간 빠른 응답을 요구한다.
▶ OLAP의 요구 사항들
- 복잡한 분석 쿼리를 수행 할 때 아래와 같은 상황에서 빠른 응답이 필요할 때 사용된다.
- 데이터들은 수십억 또는 수조개의 행으로 구성 될 수 있다.
- 열의 개수가 많은 테이블
- 특정퀴리 에서 뽑은 열의 개수는 상당히 적을 때
- 컬럼수가 1000 일때 2개의 컬럼만 조회하는 경우
- 밀리초 또는 1초 안으로 결과를 반환해야 된다.
05. 설치 주의점 (Rocky Linux 9 기준)
-
공식 RPM 저장소 사용 필요
-
최신 GPG 키:
rpm --import https://packages.clickhouse.com/rpm/lts/clickhouse-signing-key.asc -
★ 키 가져오기 오류 대응 방안
-
오류:
rpm --import https://packages.clickhouse.com/rpm/clickhouse-signing-key.asc에서 HTTP 404 발생
→ 공식 문서에 해당 키 파일 URL이 더 이상 유지되지 않거나, 리포지토리 설정 자체에 이미 키가 포함되어 있어서 별도 키 가져오기 단계가 필요하지 않을 수 있음. -
대응 방법
-
리포지토리 추가만으로 설치 시
gpgcheck가 통과되는지 확인 -
필요한 경우 대체 키 URL 검색하거나, 리포지토리 설정 파일 내
gpgkey=항목 확인 -
임시 테스트 환경이라면
gpgcheck=0옵션으로 리포지토리 설정하여 설치 가능하지만 운영환경에서는 권장되지 않음
-
-
2. 서비스 설치 및 실행
01. Update
# dnf update -y
02. Repository 추가
# dnf install -y yum-utils
# yum-config-manager --add-repo https://packages.clickhouse.com/rpm/clickhouse.repo
03. 설치
# dnf install -y clickhouse-server clickhouse-client
04. 서버 시작
# systemctl enable --now clickhouse-server
# systemctl status clickhouse-server
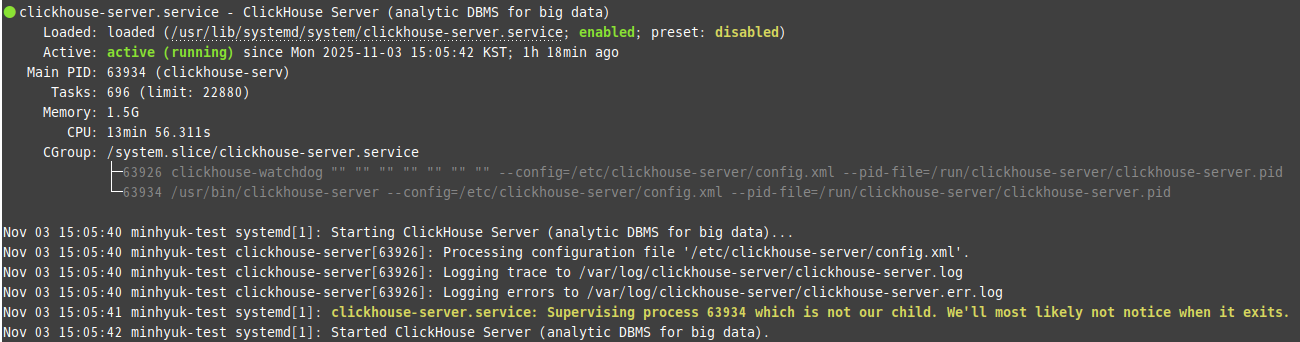
05. 클라이언트 접속
# clickhouse-client

2. 데이터베이스/테이블 생성
2-1. 데이터베이스 생성
2-2. 테이블 생성
결과: Ok.
3. 데이터 삽입
3-1. 샘플 데이터 삽입
결과: Ok.
3-2. 대량 데이터 삽입 (10,000건)
결과: 데이터 정상 삽입
// 주의 사항 = 위 명령어 실행 시 클라이언트 외부에서 실행 후 클라이언트 재진입하여 확인하여야 정상 동작함
3-3. 데이터 확인
결과:
┌─COUNT()─┐
1. │ 10003 │
└─────────┘
4. 조회 및 집계
4-1. 일부 데이터 조회
결과
4-2. 이벤트별 집계
결과:
5. 시스템 및 성능 정보
5-1. 파티션 정보 확인
결과 요약:
-
파티션: 2025-11-03
-
블록 수: 2 (1: 3 rows, 2: 10,000 rows)
-
압축: LZ4
-
데이터 경로:
/var/lib/clickhouse/store/...
5-2. 테이블 저장 용량
결과
┌─table───────┬─size_bytes─┐
1. │ user_events │ 71131 │
└─────────────┴────────────┘
1 row in set. Elapsed: 0.007 sec.
5-3. 쿼리 실행 계획
결과 예시:
┌─explain────────────────────────────────────────────────────────────┐
1. │ Expression ((Project names + Projection)) │
2. │ Expression ((WHERE + Change column names to column identifiers)) │
3. │ ReadFromMergeTree (testdb.user_events) │
└────────────────────────────────────────────────────────────────────┘
3 rows in set. Elapsed: 0.005 sec.
6. 실습 정리
이번 실습을 통해 ClickHouse를 Rocky Linux 9 환경에 설치하고, 데이터베이스 및 테이블 생성, 대량 데이터 삽입과 집계 쿼리 실행까지 실습하였다.
실습 결과, ClickHouse는 대용량 데이터 조회와 집계에 매우 효율적이며, SQL 유사 쿼리로 손쉽게 데이터를 분석할 수 있음을 확인하였다.
이번 경험을 통해 OLAP 환경에서의 데이터 처리 구조와 MergeTree 엔진 기반 저장 방식을 이해할 수 있었으며,
실제 로그 분석이나 통계 집계 시스템 구축 시 ClickHouse를 활용할 수 있다는 점을 확인하였다.
향후에는 분산 서버 구성, 다양한 엔진 활용, Grafana 연동 등을 통해 실무 데이터 분석 환경으로 확장할 수 있을 것으로 기대된다.
※ 참조 링크
https://clickhouse.com/docs/intro