






스마일 서브 CloudV 상품 중 AMD Green 16T A5 BMv1 사양을 기준으로 CPU와 별도로 GPU와 VRAM 을 활용해 AI 도구를 설치하고 사용하는 방법을 안내드리고자 합니다.
설치한 모델은 Ollama + Gemma3 이며, 서버운영체제는 Ubuntu 24.04를 기반으로 구성했습니다.
VRAM 설정
1. VRAM 설정을 위해 서버의 BIOS 화면으로 진입하여 설정합니다.
BIOS > Advanced > GFX Configuration
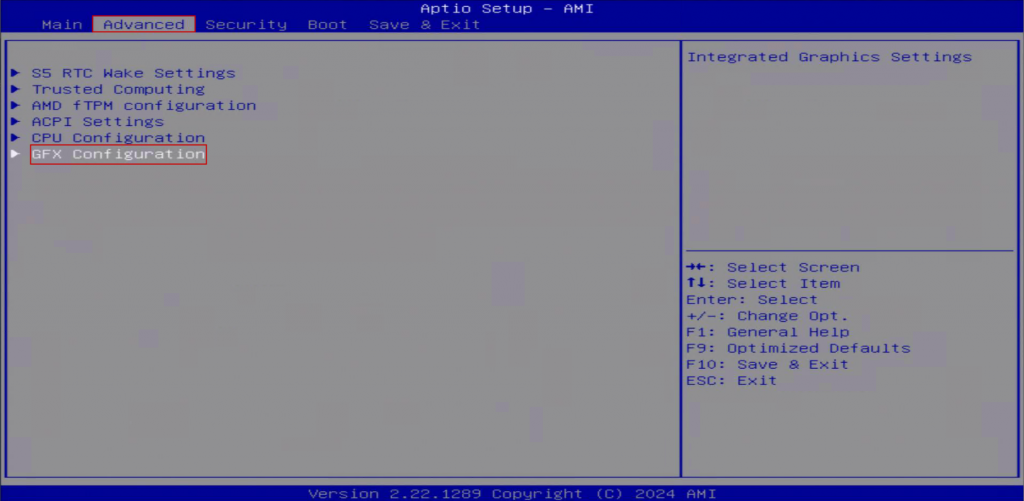
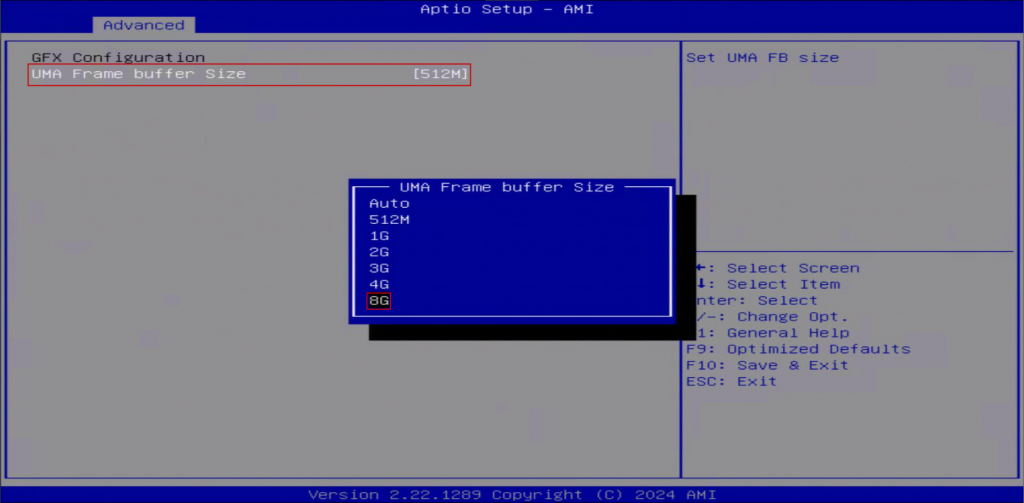
2. VRAM 을 설정할 수 있는 최대 용량으로 변경 후 부팅합니다.
UMA Frame buffer Size [ 512M ] -> [ 8G ]
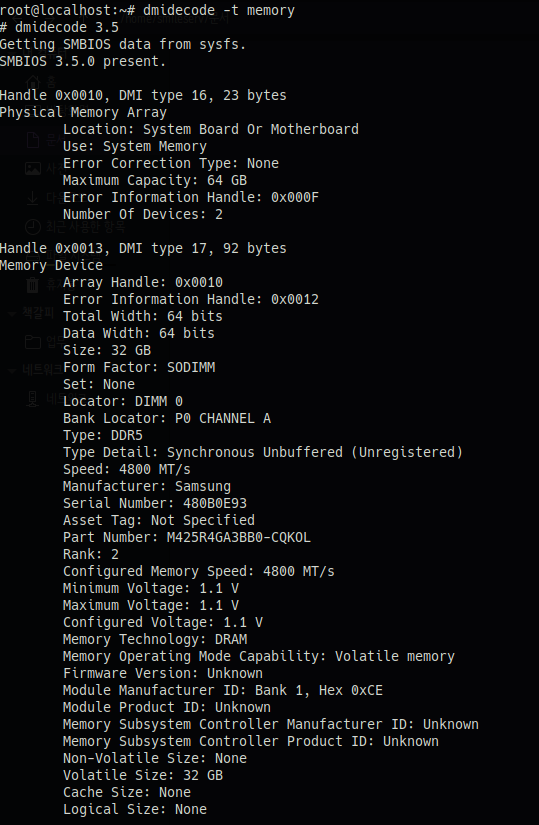
3. 부팅 후 메모리 확인
1) 서버에 장착된 메모리 확인
2) VRAM 과 나머지 메모리 확인
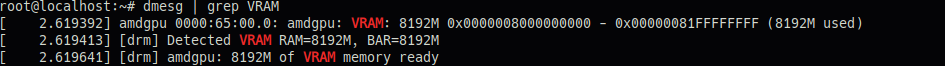

AMD GPU 드라이버 및 ROCm 설치
1. AMD GPU 드라이버 및 ROCm 설치 전 사전 작업
1) DKMS 모듈 빌드를 위한 커널 헤더 및 모듈 설치
# apt -y install “linux-headers-$(uname -r)” “linux-modules-extra-$(uname -r)”
2) Python 기반 ROCm 구성 요소 설치에 필요한 빌드 도구 설치
# apt -y install python3-setuptools python3-wheel
3) 사용자에게 GPU 장치 접근 권한 부여
# usermod -a -G render,video $LOGNAME
4) AMD 공식 GPU 드라이버 설치 도구 다운로드
# wget https://repo.radeon.com/amdgpu-install/6.3.2/ubuntu/noble/amdgpu-install_6.3.60302-1_all.deb
5) 설치 도구 패키지 로컬 설치
# apt -y install ./amdgpu-install_6.3.60302-1_all.deb
6) AMD 저장소 등록 후 패키지 목록 갱신
# apt update -y
# apt upgrade -y
2. AMD GPU 드라이버 및 ROCm 설치 및 적용
1) AMD GPU 드라이버와 ROCm 설치
# apt -y install amdgpu-dkms rocm
** 설치 후 변경사항 반영을 위해 재부팅을 진행합니다.
2) GPU 장치명 확인 (OpenCL 기준)
![]()
3) GPU 제품명 확인 (ROCm 기준)

4) GPU 상태 확인 (온도, VRAM 사용량, 클럭 등)

5) VGA 장치 확인
![]()
6) GTT 확인
![]()
Ollama + ROCm용 컨테이너 이미지 빌드 및 실행
* ROCm기반 Docker이미지를 빌드하기 때문에 서버에 Docker가 설치되어 있어야 합니다.
1. Ollama의 AMD ROCm 지원 Dockerfile 저장소 클론
# git clone https://github.com/rjmalagon/ollama-linux-amd-apu.git
2. ROCm 기반 Docker 이미지 빌드
# cd ollama-linux-amd-apu/
# DOCKER_BUILDKIT=1 docker build –build-arg FLAVOR=rocm .
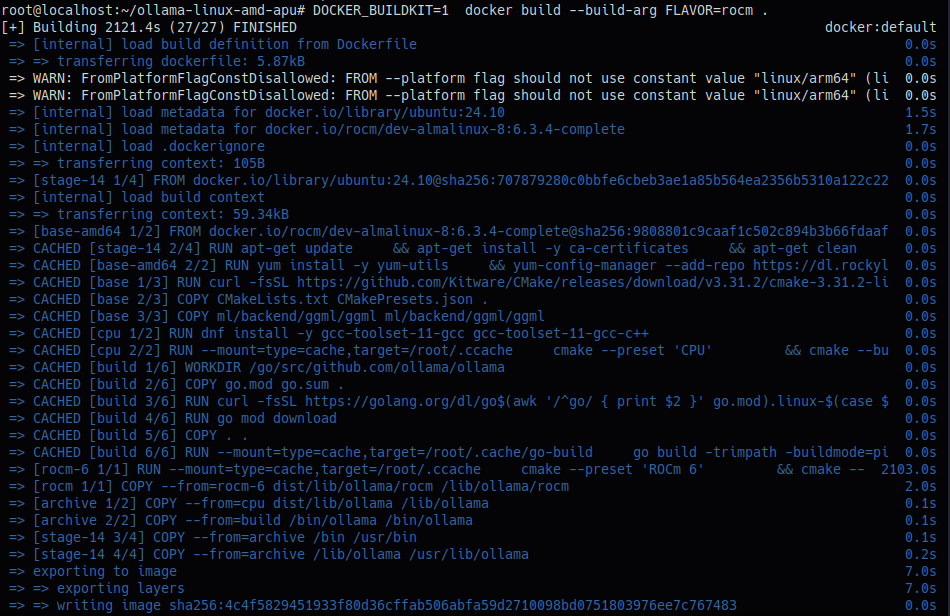
3. Docker 컨테이너 실행 (ROCm GPU 활용)
1) IMAGE ID 확인

2) ROCm GPU 접근 권한 부여하여 컨테이너 실행
# docker run -d –device /dev/kfd –device /dev/dri -e HSA_OVERRIDE_GFX_VERSION=”11.0.1″ -p 127.0.0.1:11434:11434 –name rocm-container [Image ID]
![]()
3) 확인


Gemma3 모델 실행
1. Gemma3 모델 다운
# docker exec -it rocm-container bash
# ollama pull gemma3

2. Gemma3 테스트
1) Gemma3 모델 실행
# ollama run gemma3
![]()
2) 테스트

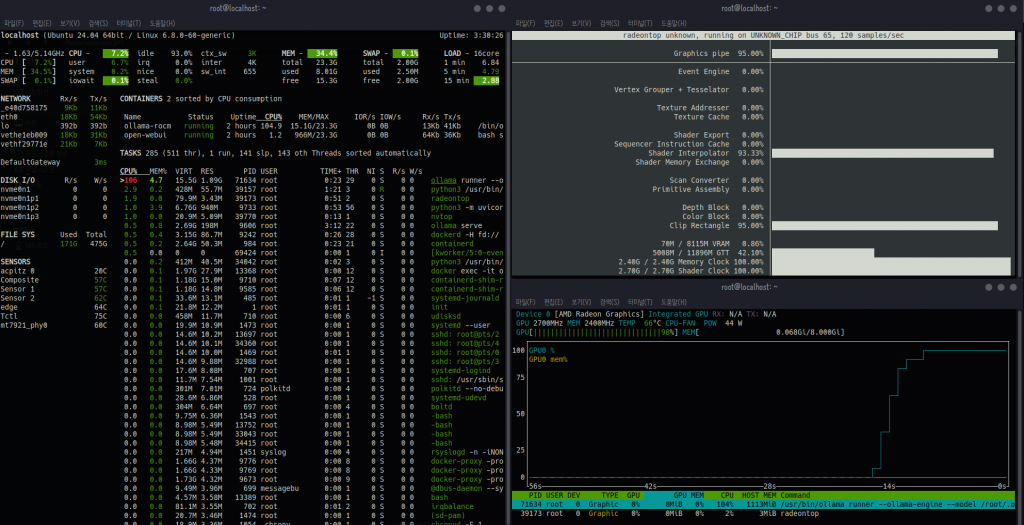
– Ollama ps 명령어로 실행 상태와 GPU 사용률을 확인할 수 있습니다.
![]()
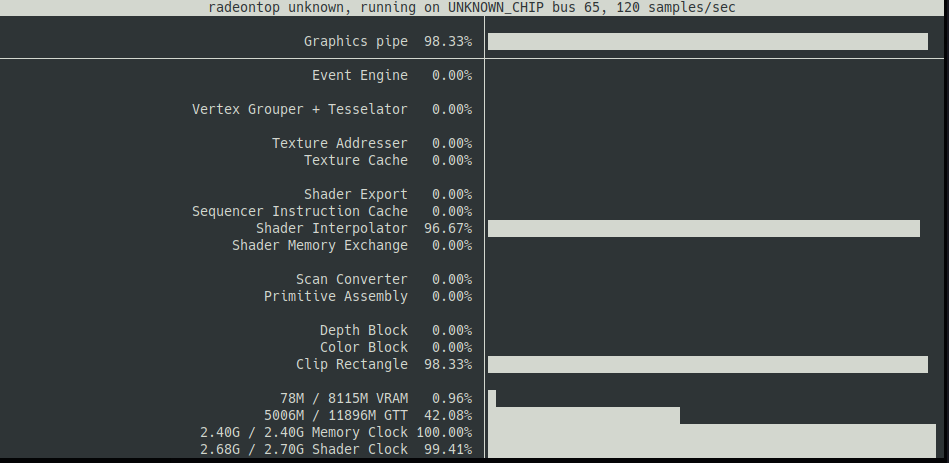
– radeontop 명령어를 통해 AMD GPU의 실시간 사용률을 모니터링할 수 있습니다. (GPU 전체 사용률, VRAM 사용량들을 확인할 수 있습니다.)
Open WebUI 연동하여 테스트
서버 내 테스트를 완료했으므로, 이제 실사용을 위한 웹 인터페이스를 설정합니다.
Open WebUI를 설치하고 연동하여, ChatGPT와 같은 익숙한 환경에서 AI 모델을 편리하게 활용할 수 있도록 구성해 보겠습니다.
1) docker-compose.yml을 이용한 서비스 통합
💡 Ollama와 Open WebUI의 효율적인 연동을 위해, 기존의 개별 컨테이너 구성을 docker-compose기반으로 전환합니다.
docker-compose.yml 파일을 사용하면 여러 컨테이너의 설정과 네트워크를 한번에 정의하고 관리할 수 있어 배포가 매우 용이해집니다.
기존 컨테이너를 중지 및 삭제한 후, docker-compose를 통해 두 서비스를 동시에 시작하겠습니다.
# docker stop rocm-container
# docker rm rocm-container
# docker images

# docker tag 27741eba730e ollama-rocm-apu:latest
# vi docker-compose.yml
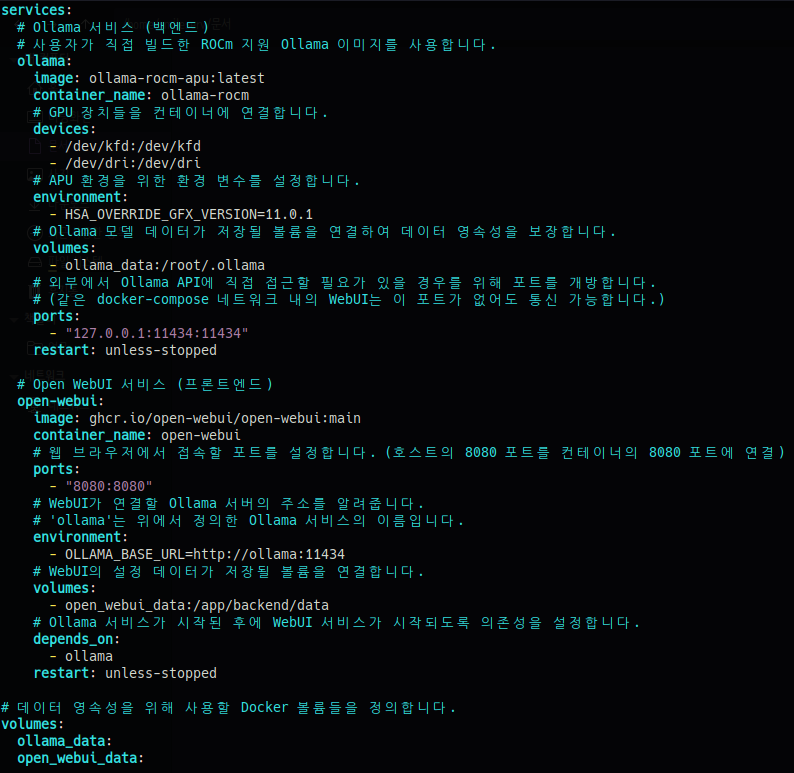
# docker compose up -d


![]()
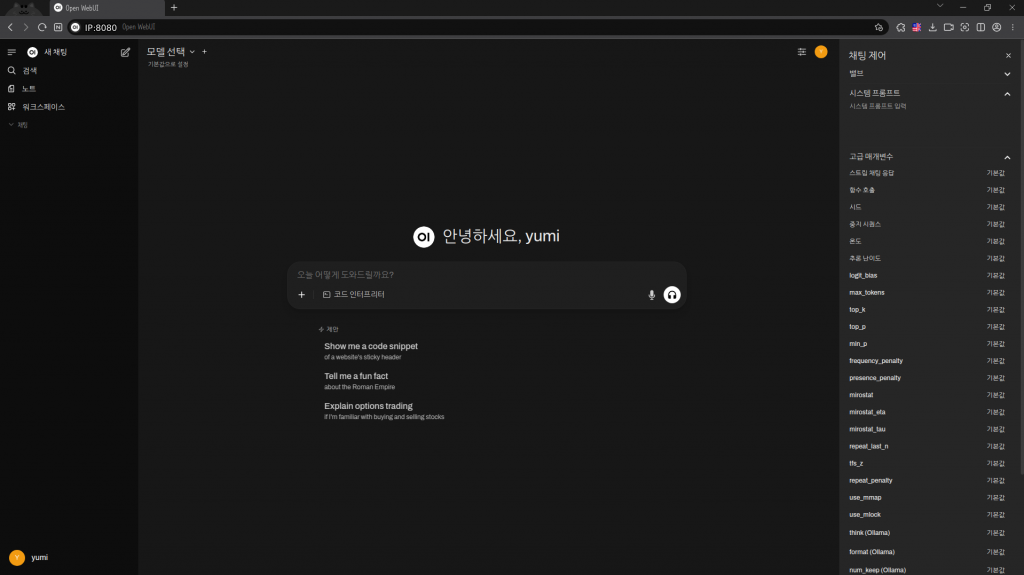
2) web 접속하여 관리자 계정 생성
– 웹에서 localhost IP:8080 으로 접속

– 계정 생성 후 접속
* 기본계정은 따로 생성되어있지 않아 계정을 생성해야 합니다.
컨테이너가 실행되고 최초로 가입하는 계정이 관리자(Admin) 계정이고, 그 뒤로 가입하는 계정은 기본적으로 관리자 계정의 허가가 필요합니다.
3) 테스트할 AI 모델 선택 및 설치
– 서버에서 실행할 AI 모델을 선택합니다.
Ollama는 공식 라이브러리 페이지(https://ollama.com/search)를 통해 설치 가능한 모든 모델의 목록과 정보를 제공합니다.
– ollama 컨테이너로 들어가서 모델을 설치합니다.
# docker exec -it ollama-rocm bash
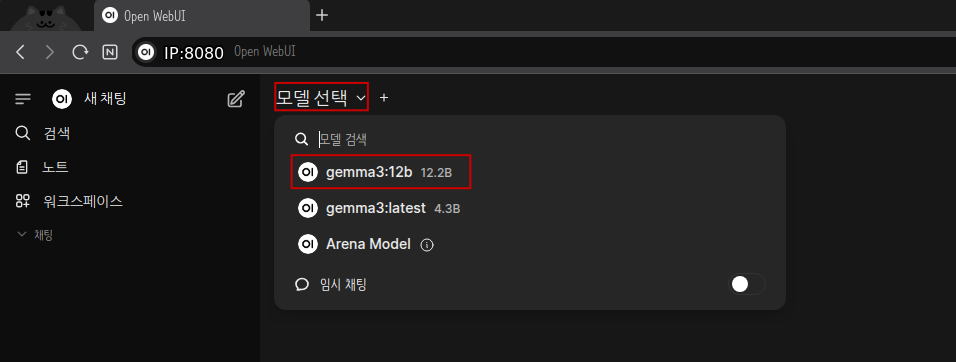
# ollama run gemma3:12b

– WEB에서 새로고침을 하면 모델 선택 항목에 방금 설치한 AI 모델을 선택할 수 있습니다.
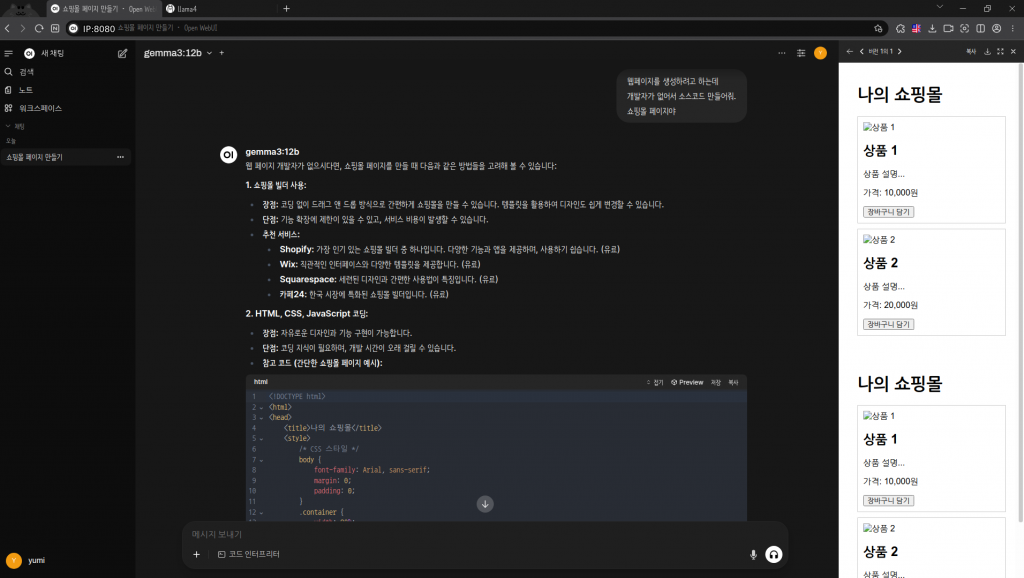
3) 테스트 및 모니터링
![]()
** 사용한 모니터링 목록입니다.
여러 모니터링 툴이 있으니 아래 목록은 참고하시면 됩니다.
– nvtop : top 과 유사한 UI, 실시간 모니터링에 최적입니다. 현재 어떤 모델/프로세스가 GPU를 얼마나 쓰는지 한눈에 파악할 수 있습니다.
– radeontop : 기본적인 GPU 사용률을 간단하게 확인이 가능합니다.
– glances : CPU, RAM, 네트워크 등 시스템 전반과 GPU를 함께 모니터링할 수 있습니다. 전체 시스템 리소스 상황 속에서 GPU 상태를 보고 싶을 때 활용할 수 있습니다.
– ollama ps : 도커 컨테이너 안의 Ollama 서버에 현재 어떤 AI 모델이 메모리에 로드(상주)되어 활성화 상태인지 보여주는 모니터링 도구이며 실행중인 모델 목록을 보여줍니다.
❗ ollama ps 모니터링에서 PROCESSPR 목록 값이 CPU/GPU 로 확인되는 의미 ❗
AI 모델중 크기가 큰 모델은 사용자의 GPU VRAM에 모두 올리기에는 부담이됩니다. VRAM이 부족하면 모델을 아예 실행하지 못하거나 시스템이 매우 느려지기 때문에 GPU오프로딩을 합니다.
GPU 오프로딩이란 모델 전체를 VRAM에 올리려고 시도하다가 공간이 부족하면 모델의 일부(레이어)를 잘라서 일반 시스템 RAM으로 보내 처리합니다.
추천드리는 AI 활용 용도
AI 모델 선택시 가지고 있는 하드웨어 성능에 비해 시스템의 VRAM이나 성능을 초과하는 모델을 구동하면, 응답 속도가 느려지거나 다른 작업에까지 영향을 미칠 수 있습니다.
따라서 현재 시스템 사양을 최대한 활용하여 최상의 경험을 제공하는 몇 가지 모델 활용 전략을 추천해 드리겠습니다.
1. 24시간 대기하는 나만의 코딩 비서 👨💻
가장 대표적인 활용법입니다. 개발 중 인터넷 검색 없이 빠르게 코드 스니펫이나 문법을 확인할 수 있어 생산성이 올라갑니다.
이렇게 질문해보세요: “파이썬에서 리스트 컴프리헨션(List Comprehension) 사용법 알려줘.” “Next.js에서 동적 라우팅(Dynamic Routing)은 어떻게 구현해?”
- 추천 모델: codegemma:2b, starcoder:1b 등 코드 생성에 특화된 경량 모델
- ✅ 핵심 장점: 인터넷이 연결되지 않은 오프라인 환경에서도 코드 참고가 가능해 보안에 유리합니다.
2. 정보의 홍수 속에서 핵심만! 요약 및 정리 📝
긴 글의 핵심을 파악해야 할 때 유용합니다. 블로그 포스트, 기술 문서, 뉴스 기사 등을 그대로 붙여넣고 요약을 요청하면 됩니다.
이렇게 활용해보세요: (긴 글을 붙여넣고) “이 내용의 핵심을 세 문장으로 요약해줘.” “이 기술 문서에서 가장 중요한 개념이 뭐야?”
- 추천 모델: gemma:2b, phi-2, tinyllama 계열
- ✅ 핵심 장점: 비교적 가벼운 모델로도 짧은 문단이나 단일 기사 정도는 빠르고 준수한 품질로 요약해 줍니다.
3. 글쓰기 막막할 때, 든든한 AI 조수 ✍️
이메일, 공지사항, 회의록 등 반복적인 글쓰기 업무의 초안을 빠르게 만들 수 있습니다. ‘AI 도우미’처럼 활용해 보세요.
이렇게 부탁해보세요: “내일 있을 주간 회의 공지 이메일 초안 좀 써줘. 주제는 OO이고 시간은…” “방금 회의한 내용인데, 이걸 바탕으로 회의록 형식으로 정리해줘.”
- 추천 모델: phi-2, mistral:7b-instruct, dolphin-2.5-mixtral (RAM 16GB 이상 권장)
- ✅ 핵심 장점: 글쓰기 초안 작업 시간을 크게 단축시키고 아이디어를 얻는 데 효과적입니다. (Tip: 입력이 길어지면 문단별로 나눠 요청하는 것이 좋습니다.)
4. 보안 걱정 없는 프라이빗 챗봇 실험실 🤖
외부 API를 사용하지 않기 때문에, 데이터 유출이나 비용 걱정 없이 자유롭게 아이디어를 테스트할 수 있습니다.
- 활용 분야: 개인 프로젝트의 챗봇 기능 테스트, 사내 기술 검증(PoC)을 위한 프로토타이핑 등
- ✅ 핵심 장점: 완전히 폐쇄된 내부 네트워크에서 작동하므로, 민감한 데이터를 다루는 아이디어도 안전하게 실험하고 검증해 볼 수 있습니다.