




최근 Openclaw 를 활용하여 텔레그램으로 단순한 대화를 넘어 나만의 비서를 구축하는 방법이 큰 인기를 끌고 있습니다.
해당 실습은 Openclaw 를 통해 나만의 비서를 구축하는 다양한 조합의 방법에 대해서 알아보도록 하겠습니다.
저는 두 가지 방법을 이용해서 이번 글을 구성해 보았습니다. 다음과 같습니다.
-
CPU + Gemini 방식 : 초기 자본 없이 가볍고 빠르게 고성능 챗봇을 도입하고 싶은 분들을 위한 세팅
-
GPU + 로컬 LLM 방식 : 향후 클라우드 서버의 실시간 로그를 수집하거나 시각적 모니터링 툴의 백엔드 데이터 등 절대 외부로 유출되면 안 되는 민감한 인프라 데이터를 완벽한 보안 환경(100% 프라이빗)에서 분석하고 싶은 분들을 위한 세팅
우선적으로 저는 CPU 서버에서 npm과 Google Gemini API를 사용하여 Openclaw 를 설치하였습니다.
첫 번째로 npm과 API를 사용한 Openclaw 로 텔레그램 챗봇을 구축하는 과정을 살펴보겠습니다.
[ 1단계 ] API 키 및 텔레그램 토큰 발급받기
1-1. 텔레그램 봇 토큰(Bot Token) 발급받기
(1) 텔레그램 앱을 실행합니다.
(2) 상단 검색 아이콘을 누르고 @BotFather를 검색합니다. (반드시 이름 옆에 공식 인증 마크인 파란색 체크가 있는 봇을 선택)
(3) 대화방에 입장하여 하단의 시작 버튼을 누르거나 입력창에 /start라고 입력 후 전송합니다.
(4) /newbot이라고 입력 후 전송합니다.
(5) 봇 이름(Name) 설정 : 채팅방 목록에 표시될 봇의 이름을 입력합니다. (한글/영문 입력 가능)
(6) 봇 아이디(Username) 설정 : 다른 사람이 봇을 검색할 때 쓸 고유 아이디를 입력합니다. (반드시 마지막이 bot이나 _bot으로 끝나야 함)
(7) 아이디 생성이 완료되면 BotFather가 축하 메시지와 함께 다음과 같은 형식의 봇 토큰을 전송해 줍니다. 1234567890:ABCdefGHIjklMNOpqrSTUvwxYZ
1-2. Google Gemini API 키 발급받기
(1) PC 브라우저를 열고 Google AI Studio(aistudio.google.com)에 접속합니다.
(2) 사용 중인 구글 계정으로 로그인을 합니다.
(3) 화면 왼쪽 메뉴 상단에 있는 Get API key(또는 API 키 발급) 버튼을 클릭합니다.
(4) 팝업창에서 새 프로젝트로 지정 후 키 이름을 설정합니다.
(5) 키 만들기 버튼 누르고 잠시 기다리면 AIzaSy…로 시작하는 긴 텍스트 Gemini API가 생성됩니다.
[ 2단계 ] 운영체제 업데이트 및 필수 엔진 설치하기 (터미널)
- 시스템 패키지 업데이트 및 업그레이드
sudo apt update && sudo apt upgrade -y - 필수 유틸리티 설치
sudo apt install -y curl wget git build-essential - Node.js 엔진 설치
curl -fsSL https://deb.nodesource.com/setup_22.x | sudo -E bash –
sudo apt install -y nodejs
OpenClaw 실행에 필수적인 최신 자바스크립트 엔진(Node.js 22.x 버전)의 공식 저장소를 서버에 추가하고 설치합니다.
설치 후 node -v / npm -v 명령어로 버전 숫자가 나오면 기초 공사 성공 !
[ 3단계 ] Openclaw 설치
- Openclaw 글로벌 설치 (Node.js의 패키지 관리자 npm을 이용해서 Openclaw를 서버 전체에서 사용할 수 있도록 정식 설치)
sudo npm install -g openclaw
설치 완료 후 openclaw –version 명령어로 2026.x.x처럼 버전이 정상적으로 출력되면 설치 성공 !
(npm을 설치한다면 openclaw 명령어 앞에 npx를 붙이지 않아도 됨)
[ 4단계 ] Openclaw 설정
- 설정 마법사 실행
openclaw configure=> openclaw 설정 시작 !
처음 실행 시 Proceed? (y)가 나오면 y를 치고 엔터 누르기 - 마법사 선택 가이드 (방향키와 엔터키 사용)
Security warning — Continue? ————————– Yes (보안 경고 확인)
Onboarding mode ————————————— QuickStart (빠른 설정 모드)
Where will the Gateway run? ————————— Local (this machine)
Select sections to configure ————————– Model (두뇌 설정 시작)
Model/auth provider ———————————– Google
Google auth method ———————————— Google Gemini API key
Enter Gemini API key ———————————- (메모해 둔 AIzaSy… 키 마우스 우클릭으로 붙여넣기)
Models in /model picker (multi-select) —————- gemini-2.5-flash(간단한 대화) 또는 gemini-2.5-pro(복잡한 코딩도 가능) 선택
Select sections to configure ————————– Channels (소통 창구 설정 시작)
Channels ———————————————- Configure/link
Select a channel ————————————– Telegram (Bot API)
Enter Telegram bot token —————————— (메모해 둔 123456… 토큰 마우스 우클릭으로 붙여넣기)
Select a channel ————————————– Finished (채널 설정 완료)
Configure DM access policies now? (default: pairing) — Yes
Telegram DM policy ———————————— Open (public inbound DMs) (★핵심: 복잡한 승인 절차 없이 누구나 바로 말 걸 수 있게 문 열기)
Select sections to configure ————————– 맨 아래 Continue 선택하여 마법사 종료
[ 5단계 ] 한도 초과 에러 원천 차단
gemini model 이 확실하게 바뀌지 않았을 경우에는 봇의 기본 두뇌가 무거운 실험용 모델로 잡혀 있어, ‘API Rate Limit (한도 초과)’ 에러가 발생할 가능성이 큽니다.
이를 방지하고 원하는 gemini 모델로 확실하게 교체하기 위해서 아래와 같은 명령어를 openclaw 실행 전에 실행시킵니다.
openclaw config set agents.defaults.model.primary “google/gemini-2.5-flash”
[ 6단계 ] Openclaw 시동 및 성공 확인
openclaw gateway
< 성공 확인 프로세스 >
1. 터미널 로그 화면에 파란색 글씨로 [gateway] agent model: google/gemini-2.5-flash라고 뜨는지 확인
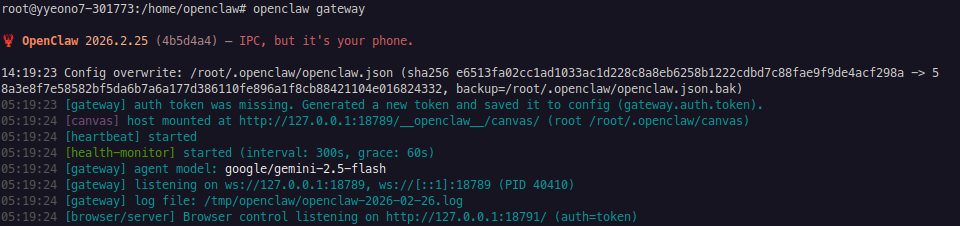
2. 텔레그램을 열고, 내 봇 대화방에 들어가서 “안녕?” 이라고 말을 건넴
3. 1~2초 만에 Google Gemini의 지능이 담긴 한국어 대답이 날아온다면 성공 !

지금까지 CPU 서버를 이용한 Openclaw 실행 방법에 대해서 설명하였고, 이어서 GPU 서버에서 llm을 이용한 방법을 소개해 드리도록 하겠습니다.
NVIDIA RTX 4090 GPU 자원을 100% 활용하여 Openclaw 로 텔레그램 챗봇을 구축해 보았습니다.
지금부터는 두 번째 방법인 npm과 LLM를 사용한 Openclaw 로 텔레그램 챗봇을 구축하는 과정을 살펴보겠습니다.
* 저는 같은 텔레그램 챗봇 API를 사용해서 콘솔에서 가상서버 status는 off로 해두었습니다. *
[ 1단계 ] 운영체제 업데이트 및 필수 엔진 설치하기 (터미널)
1. 시스템 패키지 업데이트 및 업그레이드
sudo apt update && sudo apt upgrade -y
2. 필수 유틸리티 설치
sudo apt install -y curl wget git build-essential
3. Node.js 엔진 설치
curl -fsSL https://deb.nodesource.com/setup_22.x | sudo -E bash –
sudo apt install -y nodejs
OpenClaw 실행에 필수적인 최신 자바스크립트 엔진(Node.js 22.x 버전)의 공식 저장소를 서버에 추가하고 설치합니다.
설치 후 node -v / npm -v 명령어로 버전 숫자가 나오면 기초 공사 성공 !
[ 2단계 ] Ollama 설치 및 모델 설치
1. Ollama 설치
공식 설치 스크립트를 서버에 직접 내려받아 실행 (출처 : Ollama 공식 Linux 설치 문서)
curl -fsSL https://ollama.com/install.sh | sh
2. Ollama 모델 qwen3.5:27b 설치
ollama pull qwen3.5:27b
GPU 서버 사양에 맞게 실습한 결과 qwen3.5:27b | qwen2.5:32b | qwen2.5:14b 3가지 모델이 가장 안정적이었습니다.
– qwen2.5:32b : 압도적인 심층 추론과 완벽한 한국어를 구사하지만, 현재 VRAM 환경에서는 메모리 초과로 인해 실시간 서비스가 불가능한 수준의 속도 저하가 발생함
– qwen2.5:14b : 지능과 응답 속도의 완벽한 타협점을 찾아낸 실전 최적화 모델이지만, 프롬포트 제어를 확실히 해줘야 함
해당 실습에 사용한 서버에서 가장 좋은 성능을 보였던 qwen3.5:27b를 추천드립니다.
[ GPU: 1 GPU, CPU: 8 vCPU, RAM: 60 GB, HDD: SSD 100 GB, NETWORK: 10 Gbps => 실습한 서버 사양 ]
[ 3단계 ] Openclaw 설치
1. Openclaw 글로벌 설치 (Node.js의 패키지 관리자 npm을 이용해서 Openclaw를 서버 전체에서 사용할 수 있도록 정식 설치)
sudo npm install -g openclaw
설치 완료 후 openclaw –version 명령어로 2026.x.x처럼 버전이 정상적으로 출력되면 설치 성공 !
(npm을 설치한다면 openclaw 명령어 앞에 npx를 붙이지 않아도 됨)
[ 4단계 ] Timeout 방지
1. AI 모델 예열 (Timeout 방지 기술)
마법사 연결 실패를 방지하는 명령어입니다.
curl -X POST http://127.0.0.1:11434/api/generate -d ‘{“model”: “qwen3.5:27b”, “prompt”: “hi”, “stream”: false}’
< 동작 원리 >
모델을 가동하기 위해 시스템 내부망(127.0.0.1:11434)으로 가벼운 질문(hi)을 전송합니다. 이 명령어는 SSD에 누워있던 4.7GB의 뇌를 GPU 메모리(VRAM) 위로 강제로 끌어올려, 이후 설정 단계에서 시스템이 지연(Timeout)되는 것을 완벽하게 막아줍니다.
[ 5단계 ] Openclaw 설정
설정 마법사 실행
openclaw configure
=> openclaw 설정 시작 !
처음 실행 시 Proceed? (y)가 나오면 y를 치고 엔터 누르기
마법사 선택 가이드 (방향키와 엔터키 사용)
Security warning — Continue? ————————– Yes (보안 경고 확인)
Onboarding mode ————————————— QuickStart (빠른 설정 모드)
Where will the Gateway run? ————————— Local (this machine)
Select sections to configure ————————– Model (두뇌 설정 시작)
Model ————————————————- Custom Provider 선택
API Base URL —————————————— http://127.0.0.1:11434/v1 (Ollama를 OpenAI 규격으로 속이는 마법의 주소)
API Key ———————————————– ollama-local
Endpoint ———————————————- OpenAI-compatible
Model ID ———————————————- qwen3.5:27b
Endpoint ID ——————————————- custom-127-0-0-1-11434
Select sections to configure ————————– Channels (소통 창구 설정 시작)
Channels ———————————————- Configure/link
Select a channel ————————————– Telegram (Bot API)
Enter Telegram bot token —————————— (메모해 둔 123456… 토큰 마우스 우클릭으로 붙여넣기)
Select a channel ————————————– Finished (채널 설정 완료)
Configure DM access policies now? (default: pairing) — Yes
Telegram DM policy ———————————— Open (public inbound DMs) (★핵심: 복잡한 승인 절차 없이 누구나 바로 말 걸 수 있게 문 열기)
Select sections to configure ————————– 맨 아래 Continue 선택하여 마법사 종료
[ 6단계 ] 시스템 자가 검진 및 복구
1. 시스템 자가 검진 및 복구
openclaw doctor –fix
< 동작 원리 >
설정 파일에 존재할 수 있는 문법적 오류(Unrecognized key)나 폴더 권한 문제를 시스템이 스스로 검진하고 완벽한 상태로 자동 복구(–fix)합니다. 이 명령어 하나가 수많은 충돌 에러를 잠재웁니다.
[ 7단계 ] 서버 명령어 실행 Tool 추가
Openclaw 는 사용자 정의 Tool 을 통해 서버 작업을 자동화할 수 있습니다.
다음 코드를 사용하면 텔레그램 챗봇을 통해 서버 명령어를 실행할 수 있습니다.
mkdir -p ~/.openclaw/tools
nano ~/.openclaw/tools/shell_executor.js
이후 아래 코드를 붙여 넣습니다.
Esc + :wq 로 저장 후 종료합니다.
이 코드를 각자 원하는 방향성에 맞춰서 수정한다면 챗봇의 답변 방향을 수정할 수 있습니다.
[ 8단계 ] Openclaw 시동 및 성공 확인
openclaw gateway
< 성공 확인 프로세스 >
1. 터미널 로그 화면에 파란색 글씨로 [gateway] agent model: custom-127-0-0-1-11434/qwen3.5:27b 라고 뜨는지 확인
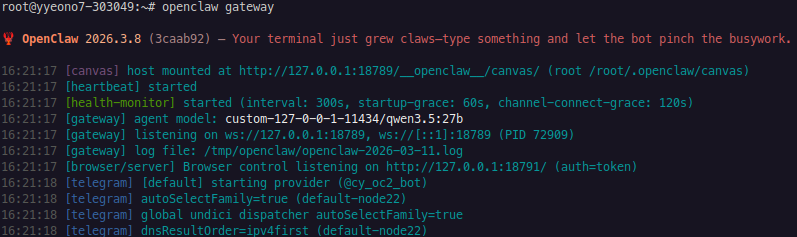
2. 텔레그램을 열고, 내 봇 대화방에 들어가서 “안녕?” 이라고 말을 건넴
3. 1~2초 만에 qwen3.5:27b 의 지능이 담긴 한국어 대답이 날아온다면 성공 !

![]()
해당 노란색 경고는 고장이 아닌 단순 메모리 알림으로 안심하고 무시하여도 됩니다.
이로써 백지 상태의 리눅스 서버에서 시작해 Openclaw , 텔레그램, AI를 연동하는 거대한 아키텍처 완성에 성공한 셈입니다.
이제 기본 뼈대는 완성되었습니다. 다음 단계로는 봇에게 나만의 시스템 프롬프트를 주입하여 성격을 부여하거나, 내 서버의 특정 폴더를 읽게 만들어 시스템 점검을 자동화하는 작업에 도전해 보시기 바랍니다.