





1. K8s ETCD 개념 정리?
ETCD 란 기본적으로 데이터베이스입니다. 분산 key-value store 로 Openstack 의 인스턴스, kubernetes 의 백엔드 시스템으로 활용하면서 그 활용도가 점점 확장되고 있습니다. ETCD는 일반적인 관계형 데이터베이스(RDBMS, MySQL, PostgreSQL, Oracle 등이 속함) 과 다르게 NoSQL(MongoDB, Cassandra, Redis)에 속합니다. 기존의 데이터베이스 형태와 etcd를 비교하자면 아래와 같습니다.
- 데이터 모델:
- 기존의 데이터베이스는 일반적으로 관계형 데이터 모델을 사용합니다. 이는 테이블과 열로 구성되어 있으며 SQL(Structured Query Language)을 사용하여 데이터를 쿼리하고 조작합니다.
- 반면에 etcd는 key-value 스토어입니다. 각 데이터는 키와 값으로 저장되며, 데이터 간의 관계를 정의하는 것이 아니라 각 데이터가 고유한 키에 의해 식별됩니다.
- 일관성 보증:
- 기존의 데이터베이스는 ACID(Atomicity, Consistency, Isolation, Durability) 원칙을 준수하여 일관성, 격리성 및 내구성을 보장합니다.
- etcd는 일관성과 가용성을 강조합니다. etcd는 일관된 읽기 및 선별적 쓰기(예: 선별적 쓰기 키를 수정하고 싶을 때만)를 지원하여 데이터의 일관성을 보장하고, 동시성을 향상시키는 동시에 시스템의 가용성을 유지합니다.
- 분산 시스템:
- 기존의 데이터베이스는 분산 환경에서 작동하기 위한 추가적인 레이어가 필요할 수 있습니다. 보통 이를 위해 분산 데이터베이스 시스템을 사용하며, 이는 여러 노드에 데이터를 분산시키고 데이터의 복제 및 일관성 유지를 담당합니다.
- etcd는 분산 시스템의 일부로서 설계되었습니다. 여러 노드에 데이터를 분산시키고 Raft(합의 알고리즘)라는 일관성 알고리즘을 사용하여 분산된 상태를 관리합니다.
- 용도:
- 기존의 데이터베이스는 주로 트랜잭션 처리 및 데이터 분석을 위한 저장소로 사용됩니다.
- etcd는 주로 분산 시스템에서의 구성 관리 및 서비스 디스커버리 등의 용도로 사용됩니다. 예를 들어 Kubernetes와 같은 컨테이너 오케스트레이션 시스템에서 구성 정보를 저장하고 공유하는 데 사용됩니다.
– 일관된 읽기 (Consistent Reads)분산 시스템에서 여러 노드에 데이터가 분산되어 있을 때, 일관된 읽기는 어떤 노드에서 읽은 데이터도 다른 노드에서 읽은 데이터와 동일하다는 것을 보장합니다. 이를 통해 시스템 전체에서 일관성 있는 데이터를 조회할 수 있습니다. – 선별적 쓰기 (Selective Writes)선별적 쓰기는 필요한 경우에만 데이터를 수정하는 방식을 의미합니다. 예를 들어, 특정 키에 대한 값 변경이 필요한 경우에만 해당 키의 값을 수정합니다. 이를 통해 데이터의 변경이 발생한 경우에만 일관성을 유지하고, 불필요한 동기화 작업을 줄일 수 있습니다. – Raft(합의 알고리즘)Raft는 분산 시스템에서 일관성을 유지하기 위해 사용되는 합의 알고리즘 중 하나입니다. 이 알고리즘은 분산 시스템에서 여러 노드 간에 동의를 이끌어내어 일관성 있는 상태를 유지하고, 장애 발생 시에도 시스템이 정상적으로 작동할 수 있도록 도와줍니다. Raft는 간단하고 이해하기 쉬운 설계로 유명하며, 널리 사용되는 합의 알고리즘 중 하나입니다. – 낙관적 동시성 제어(Optimistic Concurrency Contro)낙관적 동시성 제어(Optimistic Concurrency Control)는 데이터를 수정할 때 시스템에 잠금(Lock)을 걸지 않고, 데이터에 부여된 ‘버전 번호(Revision)’를 확인하여 충돌을 방지하는 방식입니다. 사용자가 데이터를 수정하려 할 때, 처음 읽었던 시점의 버전과 현재 저장된 버전이 일치할 때만 업데이트를 승인합니다. 만약 그 사이 다른 요청에 의해 데이터 버전이 변경되었다면 수정을 거부하고 처음부터 다시 시도하게 하여, 병목 현상 없이 데이터의 무결성을 보장합니다. |
2. key-value store
기존의 RDBMS 에 대해서 비교를 하면서 설명하도록 하겠습니다. RDBMS 로 못말려대학교의 테이블을 작성해보겠습니다.
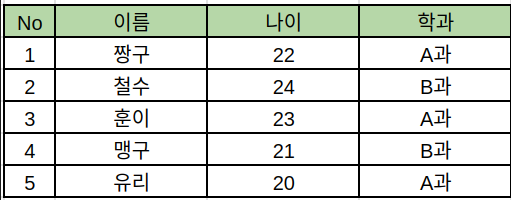
이름별로 나이와 학과 등이 작성된 모습입니다. 이중에서 A과만 시험을 보게되어, A과의 성적이 추가된다면 아래와 같겠죠
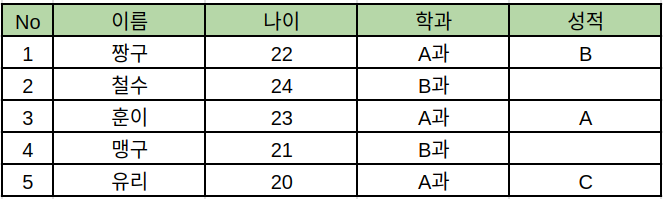
자 시간이 지나고 입대를 해야하는 친구들이 생겼습니다. 22세 이상인 학생들이 휴학계를 냈습니다. 또 컬럼을 추가해야겠군요.
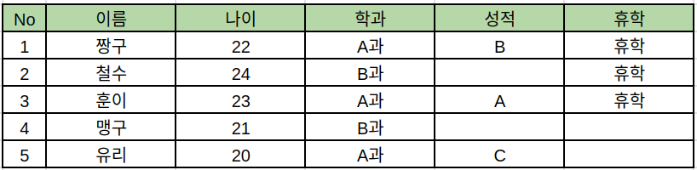
위와같이 컬럼이 추가될수록 빈공간이 생기게되고 각 컬럼은 테이블내에 있는 모든 개인에게 영향을 끼칩니다. 정작 몇몇은 해당 컬럼이 필요없는데도 말이죠. etcd는 이런 문제를 보완하고자 key-value store 형식을 채택하게 됩니다.

etcd는 위와 같이 key 와 해당하는 값(value)를 각각의 문서에 따로 보관하면서 서로에게 영향을 끼치지 않는 모습을 띄게 됩니다. 개인의 데이터를 수정한다고 또 다른 학생의 데이터를 수정할 필요가 없는 장점이 있습니다. 특정 데이터를 필요로 할경우 key-value를 데이터베이스에서 조회하여 활용하죠. 데이터가 점점 복잡해질경우 json이나 yaml 형식등을 활용하여 key-value를 업데이트 합니다.
가장 활용도가 높은 kubernetes 의 경우는 이런 방식을 활용하여 각 클러스터의 정보, Pod의 정보를 저장 하여 활용합니다.
3. 쿠버네티스와 ETCD: 상태 유지(Desired State)와 Watch 메커니즘
앞서 쿠버네티스가 ETCD의 key-value 구조를 활용하여 클러스터와 Pod의 정보를 저장한다고 언급했습니다.그렇다면 쿠버네티스는 수많은 노드와 컨테이너의 상태를 어떻게 지연 없이 실시간으로 관리하고 유지할 수 있을까요? 그 핵심은 ETCD의 Watch API 기능에 있습니다.

일반적인 시스템 아키텍처에서는 데이터의 변경 사항을 감지하기 위해 폴링(Polling) 방식을 주로 사용합니다. 즉, 주기적으로 데이터베이스에 “상태가 변경되었니?”라고 질의하는 방식입니다. 하지만 수천, 수만 개의 컨테이너가 쉴 새 없이 생성되고 삭제되는 쿠버네티스 환경에서 폴링 방식을 사용한다면 데이터베이스에 엄청난 부하가 발생할 뿐만 아니라, 상태 변화를 감지하는 데 필연적인 지연 시간(Delay)이 생기게 됩니다.
이러한 문제를 해결하기 위해 쿠버네티스는 ETCD의 Watch 메커니즘을 적극적으로 활용합니다.
쿠버네티스의 통신 중심 역할을 하는 API Server는 ETCD에 특정 Key에 대한 ‘Watch’를 걸어둡니다. 폴링처럼 계속해서 질의하는 것이 아니라, ETCD가 해당 Key에 변경(Create, Update, Delete)이 발생했을 때 이를 지속적으로 지켜보고(Watch) 있다가 API Server에 즉각적으로 이벤트를 밀어넣어(Push) 주는 방식입니다.
이 구조는 쿠버네티스의 가장 중요한 철학인 ‘원하는 상태(Desired State)’를 유지하는 데 결정적인 역할을 합니다.
예를 들어, 관리자가 “웹 서버 Pod 3개를 유지해 줘”라고 선언하면 이 정보는 ETCD에 저장됩니다. 만약 장애로 인해 Pod 1개가 다운되어 ‘현재 상태(Current State)’가 2개로 변하게 되면, 이 상태 변경 사항이 ETCD에 업데이트됩니다. ETCD는 즉시 Watch 메커니즘을 통해 API Server에 이벤트를 Push하고, 컨트롤러는 이를 전달받아 즉각적으로 1개의 Pod를 새로 생성하여 다시 ‘원하는 상태(Desired State)’인 3개로 일치시킵니다.
결과적으로 ETCD는 단순한 정적 데이터베이스를 넘어, 상태 변화에 즉각적으로 반응하여 쿠버네티스가 무중단 오케스트레이션을 수행할 수 있도록 심장처럼 박동하는 역할을 하고 있는 것입니다.
이 글은 본인의 실제 경험과 학습을 기반으로 작성하였으며, AI는 참고용으로만 활용하였습니다.